Live and Non-Real-Time Source Separation Effects for Electroacoustic Music
Source separation algorithms for audio, which attempt the extraction of constituent streams from within a complex sound scene, have many compositional applications in sound transformation. Nascent polyphonic transcription technology is commercially available (e.g., AudioScore Ultimate, Melodyne’s Direct Note Access) and can sometimes enable alterations in the spectral domain, though a full re-synthesized separation of all timbral parts or sound sources in a complex recording remains open research.
Techniques to extract a cappella vocals have been explored by many home producers, such as lifting one channel from stereo (as sometimes works famously well for early Beatles stereo recordings) or forming mid/side (sum, difference) channels. More involved stream separation has been developed; much depends on multi-channel recordings, perfect extraction only being possible in theory if there are as many channels as sources/instruments/streams/parts to separate. There are techniques, however, for extraction from mono recordings using advanced linear algebra, probabilistic models or computational auditory scene analysis (Vincent and Ono 2010). As with polyphonic transcription technology, prior knowledge of musical signals of is great benefit. Whilst an inspiring research aim, perfect separation of parts from a mono source will always be unattainable and approximate.
Much of my own previous compositional work in source separation has a link to the respectable computer music career of composer-engineer Michael Casey, who has investigated such techniques as Independent Component Analysis and probabilistic latent components analysis as applied to musical signals, and also made them available to collaborators and students. 1[1. Casey’s current affiliation is to Dartmouth College and collaborators include Spencer Topei (Topei and Casey 2011) and David Plan Casals (Casals and Casey 2010); see also Maguire 2012.]
Source separation algorithms are becoming available to composers in some open source toolkits and plugins. Source separation techniques which have previously cropped up in computer music systems include Dan Stowell’s implementation of Zafar Rafii and Bryan Pardo’s research (2011) for SuperCollider (as the PV_ExtractRepeat UGen, which separates a repeating ostinato part, such as a measure loop or similar cyclical repeat, from the otherwise changing audio) and the use of spatial separation (Barry, Lawlor and Coyle 2004) in the Csound opcode pvsdemix. In the autumn of 2013, Nicholas Bryan and Ge Wang of CCRMA released ISSE, a new GUI-based interactive source separation editor based on spectral domain masking indicated by the user. 2[2. The Csound opcode pvsdemix is available on the Csound website. ISSE can be found on the SourceForge website.]
In this article, two plugins embodying live implementations of source separation for SuperCollider are introduced, alongside two compositions involving those plugins and discussion of further compositional applications. Neither of the plugins leads to perfect quality reconstruction and the reader is encouraged to try them to explore for themselves their quirks, further described below.
Two SuperCollider Implementations
Non-negative Matrix Factorisation (NMF) via the SourceSeparation UGen
A power spectrogram derived from a short-term Fourier transform can be seen as a two-dimensional matrix: the entries in the matrix are powers in time (columns) * frequency bins (rows). We can attempt the decomposition of this matrix via a method called Non-negative Matrix Factorisation (NMF), thus separating time-varying spectral data. Powers will all naturally be non-negative, and the power spectrogram is written as the product of two non-negative matrices: a matrix of source templates to be separated and a matrix representing control of their mixture over time. This expression is commonly notated via the matrix multiplication V=W*H, where V is the power spectrogram, W represents the source templates, and H the mixing of the source templates over time. Indeed, the columns of W are source spectral templates (single spectral snapshots) and the rows of H mixing coefficients over time for a given source (spectral snapshot). To illustrate, if the FFT size was 2048 samples with a hop size of 1024 samples (50% overlap of windows) at a 44,100 Hz sampling rate, and we recorded two seconds of audio, we might have 1025 frequency bins over 86 frames, that is, a power spectrogram 1025 rows by 86 columns. W would then be 1025 rows by n columns, where n is the number of sources to extract (to be chosen by the user of the algorithm), and the mixing matrix H would be n rows (one per source) by 86 columns (one per frame; each frame has coefficients for the blend of the source templates at that moment in time).
In practice, an iterative calculation process estimates the decomposition into the non-negative matrices (Lee and Seung 2001). Once W and H are found, the sources can be extracted from the originally analysed sound, or the source templates can be applied to new incoming sound (e.g., how much of prototype source X is present in novel input?). The reconstruction and comparison is done via spectral masks, that is, taking those spectral frequency bins at strengths determined by the template (Wang and Plumbley 2005).
Developing this for a real-time SuperCollider UGen is a challenge, because the calculation of the NMF requires an iterative process that may take longer than a calculation block. Fortunately, there is a possibility in SuperCollider to run background thread calculations on the synthesis server while live rendering continues in the foreground. The SourceSeparation UGen wraps up this calculation. Resynthesis is a separate process, dependent on extracting buffers containing the W and H matrices first in the non-real-time thread. Reconstruction works via spectral masking using the PV_SourceSeparationMask UGen and the pre-calculated buffers.
Although there is potential to the UGen, in practice, simply choosing as a user to extract three, or ten, streams is no guarantee that those streams will be musically well formed, that is, corresponding to clearly differentiated instruments or sound sources. It is possible for extraction to lead to spectral templates that blend characteristics of instruments within them. The templates are also single-frame spectral snapshots, and do not model the time-varying nature of distinctive sounds; though the mixing matrix H recovers some time variation, it is not a modelling of a unified time-varying auditory object, but simply a mixture of the available snapshots over time. The spectral masking reconstruction has some of the usual problems of Fourier filtering and reconstruction, such as a sound losing definition with weakened and unrealistic harmonic content (where components are missed out by the innate binary filtering of the mask). Nonetheless, achieving this algorithm in real time still opens up some possibilities: for example, spectral templates can be extracted live in a training phase and then used for spectral filtering of new sound, all during the same concert.
Median Separation
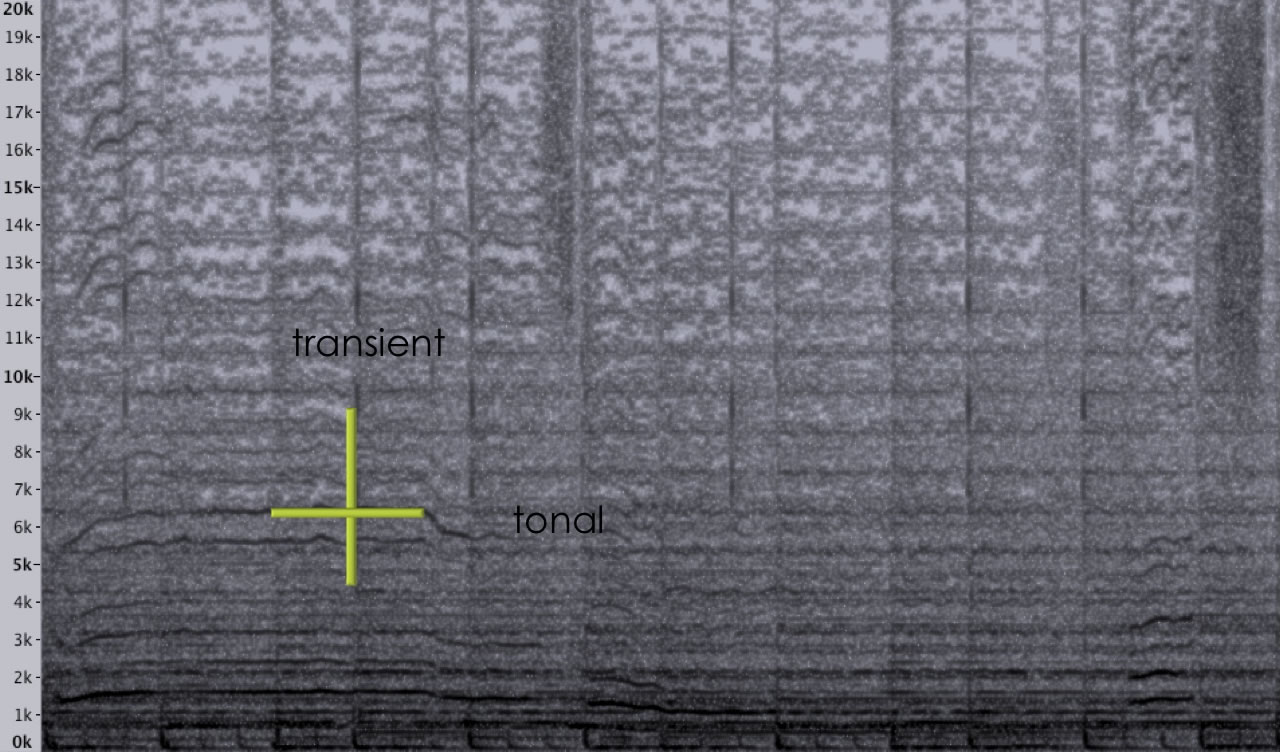
The MedianSeparation UGen allows the separation of tonal and percussive parts of a signal, following the work of Derry FitzGerald (2010). The algorithm is based on the recognition that sustained horizontal trails in the spectrum correspond to tonals, and vertical lines are transient percussive events; at each time-frequency cell, the largest of a horizontal and vertical median denotes a tonal or percussive assignment respectively. This comparison with respect to orthogonal axes is depicted in Figure 1 via the cross centred at one single time-frequency bin cell; the algorithm must run the comparison for every such cell, in real-time operation necessarily working at a delay of the number of frames over which the horizontal median is calculated.
The live implementation for SuperCollider in the MedianSeparation Ugen 3[3. Available on the SourceForge website.] is relatively efficient (20% of CPU for typical settings on an older MacBook Pro), and has been extended from the original FitzGerald paper to incorporate pragmatic options such as mean rather than median filtering (at a much reduced CPU cost) and a choice of median size, including very short sizes for low-latency application. Following FitzGerald’s suggestion, a hard (binary) or soft (blending) decision is taken in allocating a spectrogram entry to one of the two given output streams.
Although there can be artefacts in reconstructing the two streams, the sound quality of the algorithm is much improved from the earlier NMF UGen and highly applicable to complex audio targets. Piano sounds were found particularly amenable to high quality separation, with rather beautiful extraction of key-hammer onsets from the tonal body of piano sound. There is a trade-off of quality with latency and CPU cost, but it is eminently feasible to use the UGen for real-time calculation at a moderate delay (e.g., a 7 median frame calculation at 1024 hop results in a delay of around 160 ms, a 3 median frame decision at 512 hop around 35 ms).
Two Compositions Using Median Separation
Nick Collins — Supersonic Aortae
Human and machine worked together to create an extended work, formally structured in five movements (attacca), Supersonic Aortae. 4[4. Due to a love of anagrams, the title of this work could have been A Epicurean’s Torso, A Precarious Onset, Cauterise Soprano, or Arcane Opuses Riot, Recreation Soup or Up Rose Creation. Supersonic Aortae can be heard on the author’s SoundCloud page.] The machine, a programme called Autocousmatic, did most of the work (Collins 2012); the human edited the result together with around fifteen edits, with none in the first movement. The first movement was presented alone at TES 2013, uninterrupted by humanity. The sources included piano, saxophone, flute, string quartet and swing band recordings; all went through multiple stages of pre-processing by source separation algorithms, In particular, the method described above to separate percussive and tonal components of sound was developed based on research by Derry FitzGerald, so the work is dedicated to him.
Sick Lincoln — Mico Re(mi)x
The Mexican laptop duo Mico Rex combine danceable electronica, raunchy vocals and punk graphics. Their first release via the online algorithmic music label ChordPunch, the Rico Mex EP, included the track No quiero na, which was subsequently remixed by the author under his own algorithmic alias Sick Lincoln to make the Mico Re(mi)x. The reworking of the track makes extensive use of the MedianSeparation UGen in SuperCollider, which in some cases managed to extract very well the vocal parts with tonal backing from beats, and the pvsdemix opcode in Csound. Strange layerings of the separated streams were enabled by the extraction algorithms, and the composition also deployed jumps between the original full-bodied sound and single extracted streams. 5[5. Rico Mex EP is available through the ChordPunch website. Sick Lincoln’s remix is available on his SoundCloud page.]
Further Possibilities for Compositional Practice
Source separation is an exciting area for compositional exploration and there are an increasing number of freely available tools. The SuperCollider UGens detailed here work within a naturally live computer music environment, but can also be run in non-real-time mode. Indeed, experiments by the author have investigated the iterative application of MedianSeparation in particular (with varying parameter settings) to streams and sub-streams (analogous to recursive filter bank wavelet analysis formulations and other binary division procedures). Different source separation algorithms have potential to be alternated too, though spectral artefacts will multiply through such processes. Live, two (or more) complex sound sources can be cross-coupled, with streams separated from one used in processing another and vice versa; the NMF matrix technique allows spectral templates extracted from sound A to be applied against sound B, and B against A in turn.
There is reason to believe that access to sound within sound will lead to a new wave of plunderphonics, a sampling spree of minutiæ and reconstructed detail. Although there are some issues with extraction quality for streams, recognition of intended results could allow substitutive higher quality resynthesis, e.g., recognising that a flute part is nearly extracted, enough parameters of the flute may be available to then re-render via a new physical model. Feature extraction on separated streams may lead to interesting results even with some computational mishearing, and the very processes of source separation, an engineering attempt on monophonic streams to overcome a theoretical impossibility, may prove a strong human inspiration.
Bibliography
Barry, Dan, Robert Lawlor and Eugene Coyle. “Real-Time Sound Source Separation: Azimuth discrimination and resynthesis.” AES Convention 2004. Proceedings of the 117th Audio Engineering Society Convention (San Francisco CA, USA: 28–31 October 2004).
Collins, Nick. “Automatic Composition of Electroacoustic Art Music Utilizing Machine Listening.” Computer Music Journal 36/3 (Fall 2012) “Automatic Generation of Acousmatic Music,” pp. 8–23.
FitzGerald, Derry. “Harmonic/Percussive Separation using Median Filtering.” DAFx-10. Proceedings of the 13th International Conference on Digital Audio Effects (Graz, Austria: IEM — Institute of Electronic Music and Acoustics, 6–10 September 2010). http://dafx10.iem.at
Lee, Daniel D. and H. Sebastian Seung. “Algorithms for Non-negative Matrix Factorization.” NIPS 2000. Proceedings of the 14th Neural Information Processing Systems Conference (Denver CO, USA: 27–30 November 2000). MIT Press, 2001, pp. 556–562.
Maguire, Ryan. “Creating Musical Structure from the Temporal Dynamics of Soundscapes.” ISSPA 2012. Special Session at the 11th International Conference on Information Sciences, Signal Processing and their Applications (Montréal QC, Canada: 2–5 July 2012).
Plan Casals, David and Michael Casey. “Decomposing autumn: A component-wise recomposition.” ICMC 2010. Proceedings of the International Computer Music Conference (New York: Stony Brook University, 1–5 June 2010).
Rafii, Zafar and Pardo, Bryan. “A Simple Music/Voice Separation Method based on the Extraction of the Repeating Musical Structure.” ICASSP 2011. Proceedings of the 36th IEEE International Conference on Acoustics, Speech and Signal Processing (Prague, Czech Republic: 22–27 May 2011).
Topei, Spencer and Michael Casey. “Elementary Sources: Latent component analysis for music composition.” ISMIR 2011. Proceeding of the 12th International Society for Music Information Retrieval Conference (Miami FL, USA: 24–28 October 2011).
Vincent, Emmanuel and Ono, Nobutaka. “Music Source Separation and its Applications to MIR.” ISMIR 2010. Proceeding of the 11th International Society for Music Information Retrieval Conference (Utrecht, Netherlands: 9–13 August 2010). Available at http://ismir2010.ismir.net/proceedings/tutorial_1_Vincent-Ono.pdf [Last accessed 15 October 2014]
Wang, Beiming and Mark D.Plumbley. “Musical Audio Stream Separation by Non-Negative Matrix Factorization.” DMRN Summer Conference 2005. Proceedings of the Digital Music Research Network Summer Conference (Glasgow, UK: University of Glasgow, 23–24 July 2005).
Social top